
这是第二步了,第一步参考上文。这一步的目标是,以一种有意义的方式,将这些文本行组合在一起。每一行都有一个边框。每行中字的边框,决定了行的边框。就像将字组合成行一样,pdfminer.six使用边框来组合行。水平重叠的行和垂直相近的行,被组合在一起。行之间的垂直距离,由line_margin来决定。这个margin是相对于边框的高度的。
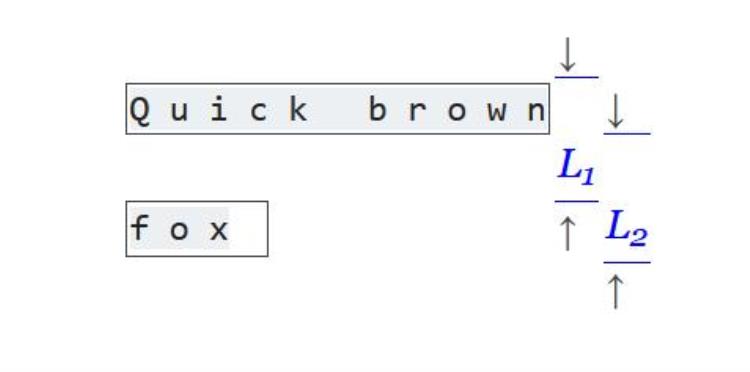
如果边框的顶部(见图L 1)和底部(见图L 2)之间的距离比绝对行距更近,则表示两行相近。这个绝对值可以是line_margin乘以边框的高度。这一步的输出为一个列表,列表中包含多个文本箱子。每个文本箱子有多行文本。最后一步,对文本箱子进行分层最后一步是,以有意义的方式对文本箱子进行分组。此步骤重复合并相邻的两个文本框。边界框的紧密程度,表现为两个文本框之间的区域(图中的蓝色区域)。

换句话说,就是这两条线周围的边界框的面积减去每条线的边界框的面积。处理旋转的字符上述算法假设所有字符具有相同的方向。然而,PDF中任何书写方向都是可能的。为了适应这一点,pdfminer.Six允许使用detect_vertical参数检测垂直写入。这将应用所有分组步骤,就好像pdf被旋转了90(或270)度。
 登录
登录
